
At the heart of all audio processing algorithms, is some notion of the quality of the results that signal. In compression, the algorithm attempts to reduce the resources(e.g. bitrate, bandwidth, etc.) required while having as little as possible impact on the input signal. In audio enhancement, the algorithm takes an input signal and attempts to produce a signal that scores better on some quality metric.
But measuring quality is hard. The perception of audio is as much a psychological process as it is also physical. Given a reference signal, we can always use the L2 distance, SNR, or some mathematically defined metric as a measure of quality. Such objective distances do not always correlate closely with how an (averaged) human listener perceives them.
Subjective Measure
Mean Opinion Score (MOS)
Since people opinions might differ, it seems reasonable to collect the opinions of multiple listeners, so as to obtain an average opinion on the quality. Expert listeners (people trained to pick up problems with audio) were asked to rate an audio sample against an original with the following scale.[1]
| Rating | Speech Quality |
|---|---|
| 5 | Excellent |
| 4 | Good |
| 3 | Fair |
| 2 | Poor |
| 1 | Bad |
The arithmetic mean is then computed to obtain the MOS.
MUSHRA
In a similar spirit of MOS, the MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA) is a method of obtaining an averaged opinion of human listeners. This test is aimed at audio files of intermediate quality. [2]
Objective Measures
While having expert human listeners in a well-controlled environment is definitely the gold standard of determining the quality of an audio clip, it's not always practical and scalable, and especially when tuning an audio processing algorithm. Here, we look at some objective measures of speech (audio) quality and their definitions. This list is by no means exhaustive.
We define $x$ as the reference signal and $y$ as the signal under test. Capital letters denote a frequency domain representation.
SegSNR (Segmental Signal-to-Noise Ratio)[3]
Defined as:
$$\frac{10}{N}\sum^N_{i=1}\left(\frac{\sum^M_jx^2_{i,j}}{\sum^M_j(y_{i,j}-x_{i,j})^2}\right)$$
Where $x$ is the reference signal and $y$ is the signal under test. Subscripts $i, j$ refers to start and end time indexes. This computes the SNR of segments and then obtains an average SNR of all segments.
LSD (Log Spectral Distance)
Defined as:
$$ \frac{1}{N}\sum^N_{i=1}\sqrt{\frac{1}{M/2+1}\sum_{j=0}^{M/2}\left(10\log_{10}\frac{|Y_{i,j}|}{|X_{i,j}|}\right)^2} $$
A frequency domain assessment of speech audio quality.[4] $X, Y$ are the STFT spectrum of the original and signal under test, subscripted by their time index $i$ and frequency bin $j$.
WSS (Weighted Spectral Slope)
$$\frac{1}{N}\sum_{j=0}^{N-1}\left(\frac{\sum_{i=1}^M W_{i,j}(S_{i,j}-X_{i,j})}{\sum_{i=1}^M W_{i,j}}\right)$$
An auditory model based frequency domain assessment of speech audio quality.[5][6] The main idea behind this algorithm is to compare the slope of frequencies grouped into weighted sub-bands.
PESQ (Perceptual Evaulation of Speech Quality)
This is a very involved objective metric with the goal of reproducing the MOS of human listeners. Several preprocessing steps were performed to align and equalize the input audio, and finally, a simple neural net is used to predict the MOS scores.[7]
Suitability of Objective Measures
A study[8] was conducted to investigate how well the objective measures listed above compared with the MOS scores. The authors found that not all objective measures correlate well with the scores given by human listeners. Some measures may correlate well on one type of noise but not the others.
3 types of noise(from TIMIT) were added to original signals, namely the white noise, factory noise, and babble noise. It was found that SegSNR performed poorly under all noise types and the following were well correlated under types:
- White Noise: LSD, WSS, PESQ
- Factory Noise: LSD, WSS, PESQ
- Babble Noise: LSD, PESQ
The authors also claimed that LSD correlates the best with human listeners.
Differences Between Speech and Music[9]
In order to better understand the perception of audio quality, it's important to understand some properties of audio signals. Equipped with an understanding of the statistics of audio signals, we can then apply these models to enhance or regenerate missing components, thereby improving the perceived audio quality. We can broadly classify audio into 2 categories, namely speech and music. We will look at how these signals can be modelled and also some characteristics of sounds and audio.
Speech Signals
Speech is an important form of human communications. Due to its importance, there is a wealth of studies on its properties, specialized algorithms are often created just for speech signals alone. PESQ, above, is just one example. Applying PESQ to music probably will not give you a reliable score.
A good quality speech signal should be natural sounding and intelligible. Speech signals can be split into 2 components, the voiced component, modelled as an impulse train of the speaker's pitch, and noise-like unvoiced components, modelled by a white noise generator (Figure 1).

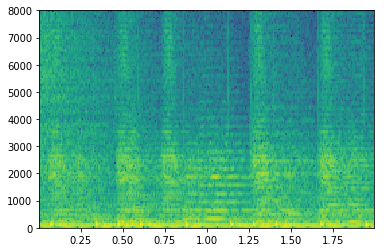
While the fundamental frequency of human speech tends to be from around 85Hz to 255Hz (inclusive of both adult males and females), harmonics can be observed up to 8kHz. Energy can also be observed in even higher frequencies due to the presence of unvoiced portions of speech that isn't produced by the vocal cord. Besides segments with spectral content, the ratio of silence to non-silence time segments is also an important property.

Spectrogram of It's all Greek to me.
Music
Music, on the other hand, tends to have clear bandpass characteristics and regular temporal patterns as seen in the spectrogram. The shape of the spectrum is largely dependent on the instrument.
Spectrum of the 20s-22s segment from Mid-Air Machine - Those Who Discard the World[10]
Given the differences in the statistics of music and human speech, we should expect that objective measures of quality will differ for voice and music. In fact, ITU had also published a PEAQ measure, in a similar spirit to the PESQ for speech. I have yet to find a study on how well the objective measures compare to a (averaged) human listener's evaluation.
Final Words
With all that we are playing around with deep neural nets, selecting or designing a good loss function is paramount to the success of the network. If we were to select a loss function that doesn't reflect how human listeners perceive audio, all might be just a fool's errand.
Revisions
- 6/5/2019: Fix MathJax/Markdown problems resulting in equations not rendering
Appendix:
Implementations for computing some of the above metrics.
Github link
P. 800: Methods for subjective determination of transmission quality ↩︎
BS.1534 : Method for the subjective assessment of intermediate quality levels of coding systems ↩︎
Hansen, J. H., & Pellom, B. L. (1998). An effective quality evaluation protocol for speech enhancement algorithms. In Fifth International Conference on Spoken Language Processing. ↩︎
Beh, J., Baran, R. H., & Ko, H. (2006). Dual channel based speech enhancement using novelty filter for robust speech recognition in automobile environment. IEEE Transactions on Consumer Electronics, 52(2), 583-589. ↩︎
Klatt, D. (1982, May). Prediction of perceived phonetic distance from critical-band spectra: A first step. In ICASSP'82. IEEE International Conference on Acoustics, Speech, and Signal Processing (Vol. 7, pp. 1278-1281). IEEE. ↩︎
Kokkinakis, K., & Loizou, P. C. (2011, May). Evaluation of objective measures for quality assessment of reverberant speech. In 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2420-2423). IEEE. ↩︎
Rix, A. W., Beerends, J. G., Hollier, M. P., & Hekstra, A. P. (2001). Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 01CH37221) (Vol. 2, pp. 749-752). IEEE. ↩︎
Jie, Z., Zhao, X., Xu, J., & Yang, Z. (2014, July). Suitability of speech quality evaluation measures in speech enhancement. In 2014 International Conference on Audio, Language and Image Processing (pp. 22-26). IEEE. ↩︎
Aarts, R. M., Larsen, E., & Ouweltjes, O. (2003, October). A unified approach to low-and high-frequency bandwidth extension. In Audio Engineering Society Convention 115. Audio Engineering Society. ↩︎
Creative Commons music from http://freemusicarchive.org/music/Ask Again/Mid-Air_Machine_-_Singles/Those_Who_Discard_the_World ↩︎